CounterFeint
Multi-Agent Ad Fraud Arena · OpenEnv
GRPO
OpenEnv
Live
Auditor
Post-hoc reasoning &
plausibility auditor
plausibility auditor
Fraudster
Proposes & modifies
deceptive ads
➡
deceptive ads
📜
Shared Ad Queue
Ads accumulate here.Both agents see it.
Investigator
Investigates ads &
renders verdicts
renders verdicts
Ready
Round
-
Total Steps
-
Proposals Used
-
Grader Score
-
End Reason
-
Agent Reward Trajectories
Fraudster
Investigator
Fraudster
Adversarial ad proposer
0.00
Run a match to see fraudster actions.
📜 Ad Queue
0 ads
No ads yet
Investigator
Evidence-based reviewer
0.00
Run a match to see investigator actions.
Auditor
Post-hoc reasoning & plausibility auditor
0.00
Auditor acts after the match concludes. Run a match to see audit results.
🕑 Match Timeline
0 events
Total ads
-
Reviewed
-
Budget left
-
Step
-
Env score
-
Cum. reward
-
Cumulative Reward
Select a task and reset to begin.
Ad queue
Subject profile
Investigation findings
RL intelligence log
Take action
Verdict history
GRPO Training Curves — Qwen3-0.6B
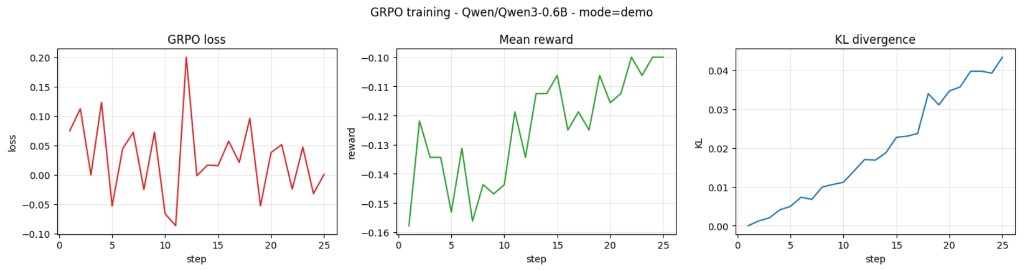
GRPO loss converges, mean reward trends upward, and KL divergence stays controlled — indicating stable policy improvement over 25 training steps.
Reward Design
| Action | Reward | Rationale |
|---|---|---|
| Investigation | -0.02 | Time/latency cost |
| Correct rejection | +0.30 to +0.40 | Scaled by severity |
| Correct approval | +0.10 | Revenue preserved |
| False positive | -0.35 | Lost advertiser revenue |
| False negative | -0.50 | Fraud goes live |
| Correct link | +0.40 | Ring detection |
Multi-Agent Reward Functions
Fraudster Reward
∑ severity × plausibility for fraud ads not rejected, minus penalty per rejected ad. Higher plausibility = more reward for evasion.
Investigator Reward
Base grader score + plausibility-weighted clean rationale bonus − capped inconsistency penalty. Track A flags strip the bonus.
Auditor Reward
Reward for true-positive flags vs ground truth, minus false-positive penalty. Deterministic rule-based scorecards.
Training Pipeline — GRPO Self-Play
🤖
Frozen Fraudster
llama3.1:8b via Ollama(8B params, frozen)
🤖
Trainable Investigator
Qwen3-0.6B + QLoRA(GRPO training)
⚖
Deterministic Auditor
Rule-based scorecards(reward source)
Sequential self-play: train one agent at a time against frozen opponents (AlphaGo paradigm)
📈 Live Match Reward Curves
Click “Run Demo Match” to generate animated reward curves from a live simulation.
🧠 Model Comparison — Investigator Reward Curves
Model comparison curves will appear here as training progresses.
Planned models: Untrained Qwen3.5-0.8B, Fine-tuned Qwen3.5-0.8B, and more.
Planned models: Untrained Qwen3.5-0.8B, Fine-tuned Qwen3.5-0.8B, and more.